Healthcare applications are the most crucial applications as they directly or indirectly deal with the life of the person. Therefore, testing of healthcare applications becomes important automatically since the end-product of testing is the end user product. Now if we talk about testing, I believe the most important thing that needs to be handled while testing is the test data which we input in the software/application. Input test data can be of any type, like – text, alphanumeric, pdf, audio, video, etc.
The power of any organization comes from the fact that, the more they input the test data into the application, the more they are prone to find issues in the application which in turn can prevent errors in production.
So, considering the above fact, the main challenge is to generate different types of test data to provide maximum test coverage for an application.
Ways to Solve the Problem
Approach 1 – Manually create the test data from the required data set with some of the best-guessed selected values, input some of those values and check how the application behaves with those input data.
Pros –
- The human mind can think of some out-of-the-box data which can help us uncover rare hidden defects.
- Experienced person can generate the test data to break the application at its best.
Cons –
- Since it is human dependent there could be a possibility of losing crucial data which may occur in production.
- Less test coverage since not all can be tested.
- The experience of testers might vary therefore some areas of application might remain untested due to a limited data set.
Approach 2 – Automatically generate the test data from the required data set and feed the same data to the application without any manual intervention which will uncover almost all the possible bugs.
Pros –
- Since test data is being generated by the code/machine, a maximum amount of test data can be generated and tested.
- Human effort is less therefore we would get faster results.
- Good test coverage.
Cons-
- Dependency on the machine to generate the test data reduces the out-of-box thinking of the human mind which might uncover the rarest bugs.
How to Use Approach 2
Here are several approaches to generate test data automatically:
1. Use of Test Data Generation Tools
There are various tools specifically designed to generate synthetic data for testing purposes.
Datafaker: A Python package that generates fake data and can be tailored to specific needs, including healthcare.
2. Custom Scripting
Write custom scripts using programming languages like Python, Ruby, or JavaScript. Libraries such as Faker (Python) or Chance.js (JavaScript) can help generate realistic data.
Python Example:
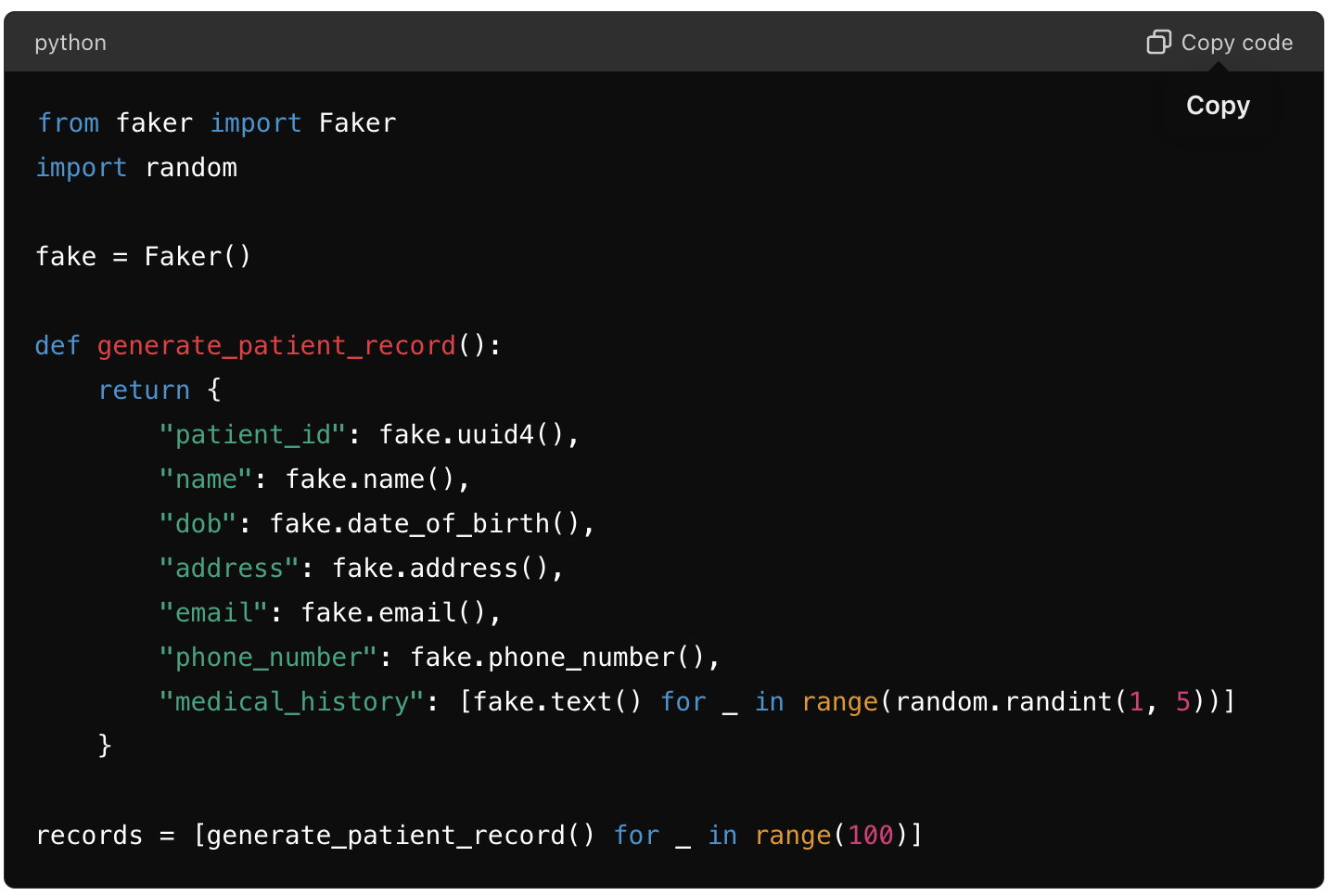
3. Database Anonymization
Use real data (for e.g. – production data if possible) but anonymize it to ensure privacy. This helps us to ensure the application is susceptible to the real time scenarios which will occur while working with the application.
Tools like ARX or NOMAD can help with data anonymization.
ARX: A comprehensive open-source software for anonymizing sensitive personal data.
NOMAD: An open-source data anonymization tool.
4. Synthetic Data Generation
Generating synthetic data that mimics real-world data patterns but does not trace back to real individuals.
Synthea: An open-source synthetic patient generator that models the medical history of synthetic patients.
5. Data Masking Tools
Tools like Informatica or Oracle Data Masking can mask sensitive information in a way that retains the characteristics of the original data.
Informatica: Provides robust data masking capabilities for various types of data.
Oracle Data Masking: Helps protect sensitive data by replacing it with realistic but scrubbed data.
6. Using APIs for Public Data
APIs from public health data sources can be utilized to fetch real but anonymized data:
CDC APIs: Provide access to a variety of public health data.
HealthData.gov APIs: Provide datasets and APIs for various health-related data.
7. Combining Real and Synthetic Data
Combine real anonymized data with synthetic data to create a comprehensive dataset.
Start with a base of real anonymized patient data.
Enhance it with synthetic data to simulate various scenarios.
Best Practices for Test Data Generation
- Data Privacy: Ensure all test data complies with relevant privacy regulations (e.g., HIPAA in the US, GDPR in Europe).
- Data Validity: Ensure the synthetic data maintains the logical consistency and integrity of real data.
- Volume and Variety: Generate enough data to cover various test scenarios, including edge cases.
- Maintainability: Write modular and reusable scripts to facilitate ongoing data generation.
- Example Workflow
- Define Schema: Determine the structure and fields required for the test data.
- Select Tools: Choose appropriate tools or libraries for data generation.
- Script Development: Write scripts to generate or fetch the data.
- Data Validation: Validate generated data for consistency and correctness.
- Integration: Integrate the generated data into your testing environment.
- By following these approaches, you can automate the process of generating realistic test data for your healthcare application, ensuring that your tests are thorough and reliable.
Conclusion
Harnessing the power of test data generation is essential for enhancing the functionality of health apps. It supports the development of more accurate, reliable, and user-friendly applications while ensuring security and compliance. Moreover, it facilitates agile development practices and supports the integration of advanced technologies like AI. As the digital health sector continues to grow, leveraging test data generation will be a crucial factor in the success and impact of health applications.