
Challenge
In recent years, healthcare providers and researchers have turned to cloud-based solutions for storing and analyzing patient data. As the amount of data being generated continues to increase rapidly, traditional relational databases are facing challenges in scaling to handle the massive amounts of data being generated. NoSQL databases offer an alternative solution for handling this data in a more flexible and scalable way. However, using NoSQL databases effectively requires a separate set of skills and best practices. Amazon DynamoDB is a popular NoSQL database choice for storing patient health-related data. However, since patient data is sensitive and must be handled with care, there are several best practices to follow when using DynamoDB. In this blog, we will discuss the best practices for using DynamoDB to store patient health data.
Options and solutions with respective pros and cons:
1. Choose the right database for your use case
When it comes to NoSQL databases, there are several options to choose from, including document-oriented, key-value, column-family, and graph databases. Each type of database has its strengths and weaknesses, and the right choice depends on your specific use case.
Document-oriented databases, such as MongoDB, are best suited for handling unstructured or semi-structured data, such as documents, images, and videos.
Key-value databases, such as Redis, are best suited for handling simple data structures, such as user sessions, cache data, and configuration data.
Column-family databases, such as Cassandra, are best suited for handling large volumes of structured data, such as time-series data, logs, and financial data.
Graph databases, such as Neo4j, are best suited for handling complex relationships between data points, such as social networks, recommendation engines, and fraud detection.
2. Design your schema based on access patterns
Unlike traditional relational databases, NoSQL databases do not enforce a strict schema. However, it is still important to design your schema based on the access patterns of your data. This means considering how you will query and update your data and designing your schema to optimize for those access patterns.
3. Use denormalization and aggregation
Denormalization and aggregation are common techniques used in NoSQL databases to optimize performance. Denormalization involves duplicating data across multiple documents or collections to reduce the need for expensive joins. Aggregation involves precomputing and storing the results of complex queries to reduce query time.
Understanding AWS (Amazon Web Services) DynamoDB better
DynamoDB is composed of several key components:
Tables
Tables are the primary data storage component in DynamoDB. They are composed of items and attributes, and each item represents a unique record in the table.
Items
Items are individual records within a table. Each item is composed of one or more attributes that define the properties of the item.
Attributes
Attributes are the basic data elements that make up an item. Each attribute has a name, and a value and can be of various data types such as string, number, or binary.
Partition key
A partition key is a primary key attribute that DynamoDB uses to partition data across multiple nodes for scalability and performance. All items with the same partition key value are stored together on the same partition.
Sort key
A sort key is a secondary key attribute that can be used to sort data within a partition. Items with the same partition key value are sorted in ascending order by the sort key value.
Secondary indexes
Secondary indexes are additional data structures that allow you to query data based on attributes other than the primary key. DynamoDB supports two types of secondary indexes: global secondary indexes (GSIs) and local secondary indexes (LSIs).
Streams
Streams provide a way to capture changes to data in real-time. When an item is added, updated, or deleted in a table, a corresponding event is generated in the stream.
Now let us look at some of the features and benefits of DynamoDB
- Scalability: DynamoDB can scale up or down automatically based on the workload. This makes it easy to handle varying levels of traffic and data volume.
- High performance: DynamoDB provides fast and predictable performance with low latency, even for large-scale datasets.
- Fully managed: DynamoDB is a fully managed service, which means that AWS takes care of the operational aspects of the service, such as backups, patching, and scaling.
- Security: DynamoDB provides several security features, such as encryption at rest and in transit, fine-grained access control, and audit logging.
- Cost-effective: DynamoDB offers a pay-per-request pricing model, which means that you only pay for the read and write requests that you make. This can result in significant cost savings compared to traditional database solutions.
DynamoDB is a powerful and flexible NoSQL database service that is well-suited for storing patient health-related data. Its scalable and high-performance architecture, coupled with its security and cost-effectiveness, make it a popular choice for many healthcare organizations.
Some best practices to follow when using DynamoDB as your NoSQL Database
Here are some best practices to follow when using DynamoDB to store and process patient data:
1. Define the data model based on access patterns
Start by understanding the data access patterns and use cases for your application. This will help you determine the optimal data model for your DynamoDB table. Define the partition key and sort the key based on the queries that you will be performing most frequently. It is important to choose a partition key that distributes your data evenly across partitions to avoid hot partitions.
2. Use secondary indexes
In DynamoDB, secondary indexes contain a subset of attributes from the table. This reduces the size of the index and improves query performance. Use secondary indexes to support different query patterns and to optimize the size of your indexes.
3. Use local secondary indexes (LSIs)
LSIs are indexes that have the same partition key as the table but a different sort key. They are useful for optimizing queries that filter or sort data within a partition. Use LSIs to reduce the number of queries required to fetch data from the table.
4. Use global secondary indexes (GSIs) judiciously
GSIs are indexes that have a different partition key and sort key than the table. They are useful for supporting different access patterns and optimizing queries across multiple partitions. However, GSIs can also increase the cost and complexity of your DynamoDB implementation, so use them judiciously.
5. Use DynamoDB Accelerator (DAX) to improve performance:
DAX is an in-memory cache for DynamoDB that can improve read performance by reducing the number of reads to the underlying DynamoDB table. Use DAX to improve query performance for frequently accessed data.
6. Use batch operations to reduce latency
DynamoDB provides batch operations to write or delete multiple items in a single request. Use batch operations to reduce the number of round trips to DynamoDB and to improve write and delete performance.
7. Monitor and optimize throughput
DynamoDB allows you to configure read and write throughput for your tables. Monitor the provisioned throughput and adjust it as needed to ensure optimal performance.
8. Implement data retention policies
Patient health-related data may have specific retention requirements based on regulatory or legal requirements. Implement data retention policies to ensure that data is retained for the appropriate duration and is deleted when no longer needed.
9. Validating data before storage
Use strong data validation Data validation is important to ensure that patient health data is accurate and consistent. You should validate all data before it is stored in DynamoDB to ensure that it is in the correct format and within acceptable ranges. For example, you might use regular expressions to validate dates, or numeric ranges to validate blood pressure readings. This can help prevent invalid data from being stored, which can lead to incorrect diagnoses and treatment.
10. DATA recovery
You should implement regular backups and disaster recovery measures for your DynamoDB tables. This is critical to ensure that patient data is not lost in the event of a disaster or hardware failure. You can use DynamoDB’s built-in backup and restore features, or you can use third-party backup tools. Additionally, you should test your backups and disaster recovery procedures regularly to ensure that they work as expected.
11. Access control
Access control is another critical component of securing patient health data in DynamoDB. You should implement strict access control policies to ensure that only authorized personnel have access to patient data. You can use AWS Identity and Access Management (IAM) to create policies that restrict access to specific resources, such as tables, items, or attributes. Additionally, you can use AWS Key Management Service (KMS) to control access to encryption keys.
12. Data encryption
Implementing data encryption is a critical component of securing patient data in DynamoDB. DynamoDB provides encryption at rest using the AWS Key Management Service (KMS). You should enable encryptions for all tables storing patient health data. Additionally, you should use client-side encryption to encrypt sensitive data before it is stored in DynamoDB. This helps ensure that the data is secure from unauthorized access.
By following these best practices, you can design and implement a DynamoDB database to store and process patient health-related data efficiently and securely.
Code and steps to do so:
Here is an example of creating a table in DynamoDB using the AWS CLI

This creates a table called “mytable” with a partition key “userid”.
To add an item to this table, you can use the put-item command:
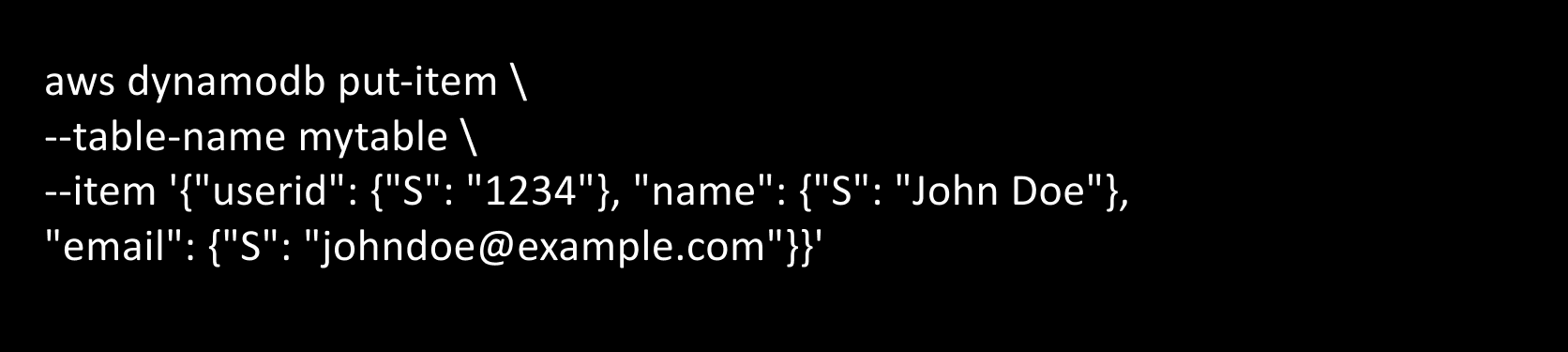
This adds an item to the table with a userid of “1234”, a name of “John Doe”, and an email of “[email protected]“.
To create a Global Secondary Index (GSI), you can use the update-table command

This creates a GSI called “email-index” on the “email” attribute. The GSI is set up with a read and write capacity of 1, but you can adjust these values based on your anticipated workload.
Conclusion
NoSQL databases like DynamoDB offer a flexible and scalable solution for handling copious amounts of data. However, using them effectively requires careful consideration of your access patterns and table design. By following the best practices outlined in this blog post, you can ensure that your DynamoDB tables are optimized for the types of queries you will be making, resulting in efficient and cost-effective use of the service.


